What to know
- Reddit has updated its robots.txt file in an effort to prevent Bing and other search engines from crawling the site.
- Reddit claims the crackdown is a result of failed agreements with search engines and companies unwilling to make enforceable promises regarding their use of Reddit content.
- Google is the only major search engine that can surface recent content from Reddit in its search results, purportedly because of their $60 million deal.
Reddit is stepping up efforts to prevent web crawlers from using its data. As a result of its crackdown, currently no major search engine, be it Bing or DuckDuckGo, can provide recent Reddit posts and comments in their search results. None except Google.
So if you tried searching for recent Reddit results in your search engine query, you’ll unfortunately come up short. Compare the search results on Bing and Google for the same query about a recent news discussion:
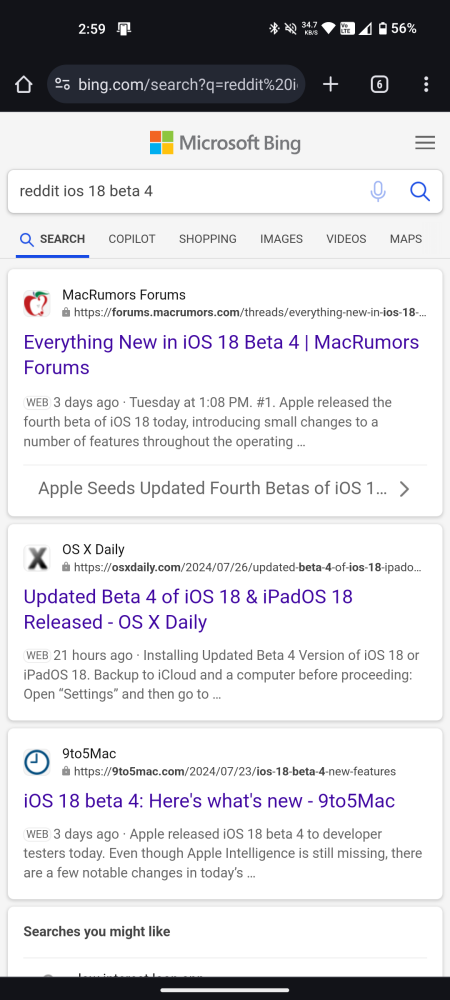
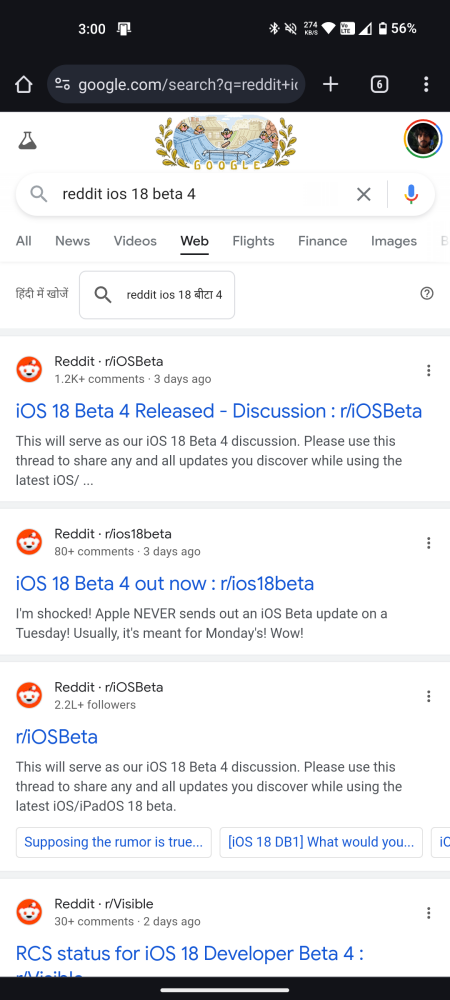
Reddit has been getting more and more protective of its data in recent times, and understandably so. Being a popular community forum where people come together to discuss and talk about their interests makes Reddit a veritable goldmine for AI training. But Reddit understands, as do the AI companies, what an invaluable resource the website is at a time when AI chatbots are taking over the web.
To protects its interests, Reddit has updated its robots.txt file to prevent web crawlers from accessing the website. This move comes after several failed attempts to reach an agreement with the different search engines regarding their use of Reddit’s content. Cracking down on search engines and stopping them from scraping data is a clear signal that those who don’t have an agreement shouldn’t be accessing Reddit content.
Right now, Google is the only major search engine that can surface Reddit posts and comments in the search results. And it’s no coincidence either. Though a Reddit spokesperson mentioned in a statement that “[t]his is not at all related to our recent partnership with Google,” it’s not easy looking past the $60 million deal that allowed Google to train its AI model on Reddit’s data. Supposedly the deal covered real-time access to Reddit’s content as well.
The message from Reddit is clear enough: Pay up, or miss out. Most companies, including Microsoft, have conceded. In a statement, Microsoft said:
“We respect the robots.txt standard. Bing stopped crawling Reddit after they implemented their updated robots.txt file on July 1, which prohibits all crawling of their site.”
Those who use non-Google search engines are at a clear disadvantage, mainly because Reddit’s own search function doesn’t work as well as search engines at finding relevant content. For the present, if you want to get recent results from Reddit using the “site:reddit.com” trick or by appending the query with the word ‘Reddit’, you’ll have to open up Google first.


