What to know
-
Claude Fable 5 is Anthropic’s first “Mythos‑class” model for general use, built on the same underlying system as the previously locked‑down Claude Mythos 5.
-
It leads public benchmarks for coding, knowledge work and long-horizon tasks, but is slower and significantly more expensive than earlier Claude models.
-
Anthropic has wrapped Fable 5 in strict safety rails, routing certain cybersecurity and biology queries back to Claude Opus 4.8 instead.
-
Early reviews praise its coding and autonomy, while Reddit and X users are split over cost, refusals and what it signals about “AI inequality”.
Fable 5 is Anthropic’s attempt to put a frontier‑level system into everyday products without unleashing its riskiest capabilities on the open internet. That balancing act – between power, safety and access – is shaping how developers, companies and ordinary users are reacting to the first public Mythos‑class model. Here’s everything you need to know about Fable 5 – what it is, some of its samples and use cases, comparisons with other models, and what people have to say about it.
How Fable 5 fits into the current AI race
Anthropic introduced Claude Mythos in April as a highly capable model it explicitly declined to release broadly, citing its ability to find and exploit software vulnerabilities at scale. Fable 5 is the public-facing version of that technology: same underlying model family, but tuned and wrapped in safeguards for general customers and subscribers.
The company describes Fable 5 as its first “Mythos‑class model made safe for general use” and says its capabilities exceed those of any model it has previously made generally available, with particular strength in software engineering, knowledge work, scientific research and vision. It is Anthropic’s answer to rising competition from OpenAI and Google, and arrives just as the company prepares for a likely IPO.
Unlike earlier Claude models, Fable 5 is explicitly optimized for long-running autonomous tasks: Google’s Gemini Enterprise Agent Platform documentation lists 1,000,000 maximum input tokens and 128,000 output tokens, with support for text, images and PDFs as inputs. That makes it one of the most capable generally available models for large codebases and complex document workflows.
Technical profile, benchmarks and pricing
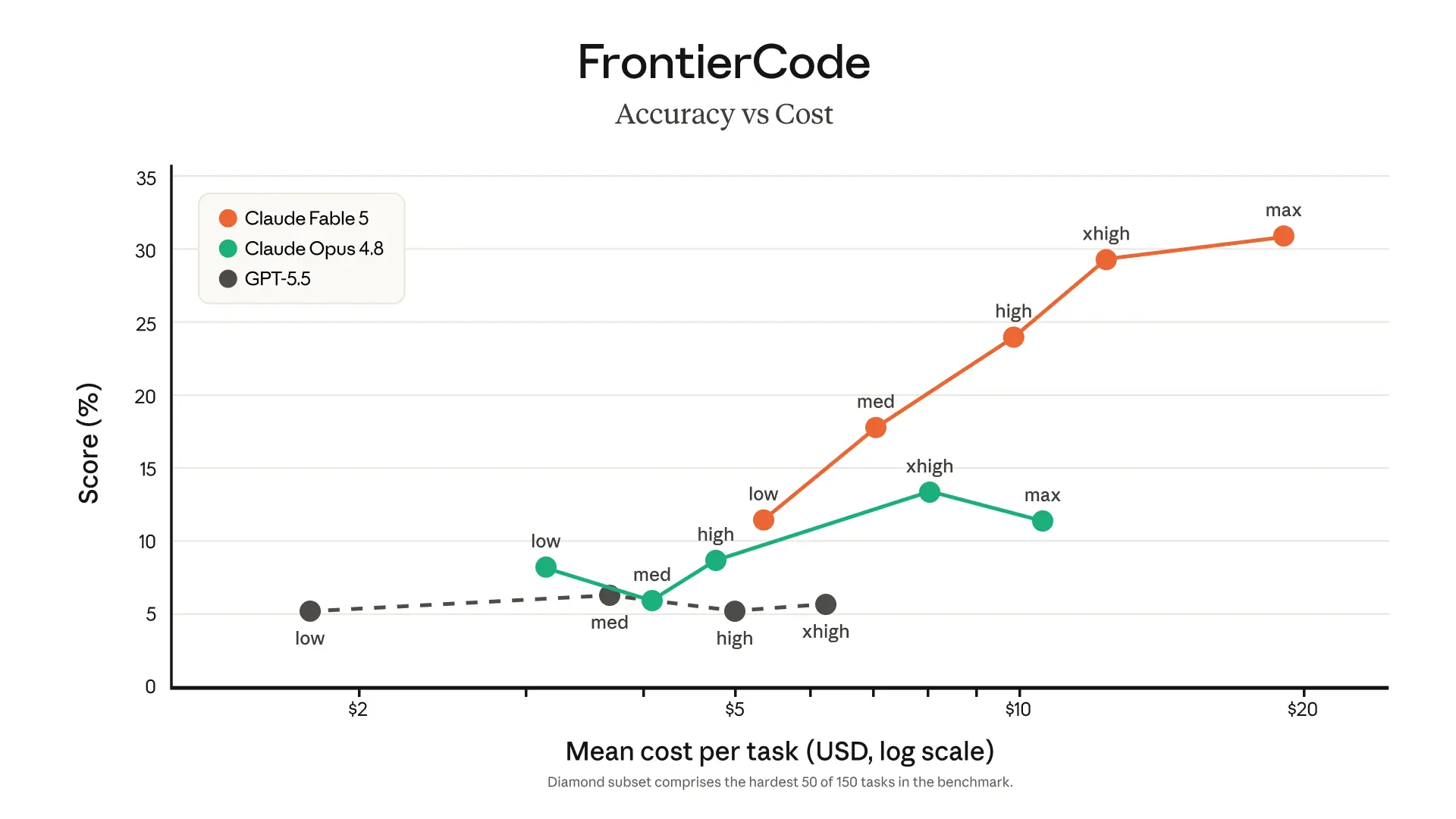
Across independent and vendor-published benchmarks, Fable 5 currently sits at or near the top of the public leaderboard.
Core specs and pricing
Multiple reports confirm that Fable 5 and Mythos 5 share pricing, which is double Opus 4.8 but less than half the price of the earlier Mythos Preview program. For now, Anthropic is offering Fable 5 as an included option for Pro, Max, Team and Enterprise subscribers through late June, after which usage will consume separate credits, subject to capacity.
That cost profile – premium but not out of reach for serious commercial workloads – shapes how users use it – as an upgrade for high‑value, complex projects rather than a drop‑in replacement for everyday chat.
Benchmark performance and model comparisons
A detailed comparison shows Fable 5 leading its peers across a range of demanding tasks.
These numbers back up Anthropic’s claim that Fable 5 is state‑of‑the‑art on “nearly all” tested capability benchmarks, with especially large gains in software engineering and long-horizon planning. At the same time, the gap over Opus 4.8 is not uniform; some benchmarks show modest 1–3 percent differences, reflecting the impact of safety constraints and fine‑tuning choices.
For businesses, the picture that emerges is clear: Fable 5 is the model to reach for when a task requires deep reasoning over large contexts, but the economics and latency may not make sense for simple prompts.
Safety rails, Mythos 5 and how Anthropic tries to contain risk
Fable 5 exists because Anthropic believes it has found a way to safely expose Mythos‑level capabilities to the public. That promise rests on a dense stack of safeguards.
The core mechanism is routing. If a prompt touches on a narrow band of high‑risk topics – cybersecurity exploitation, biological weapons, certain chemistry or attempts to bypass policy – the request is intercepted and answered instead by Claude Opus 4.8, which is tuned more conservatively. Anthropic says these guardrails trigger in under 5 percent of sessions on average, though they are intentionally over‑broad at launch, catching some harmless queries as well.
On top of that, the company has run what it describes as more than 1,000 hours of internal and external red‑teaming, including an “external bug bounty” that reportedly failed to find a universal jailbreak. To defend against future attacks, Anthropic is changing its data retention policy for Mythos‑class models: it will keep user traffic for 30 days to detect novel exploits and reduce false positives, but says it will not use that data to train new models and will log all human access.
Alongside Fable 5, Anthropic is rolling out Claude Mythos 5 to a small group of cyber‑defenders and infrastructure providers via Project Glasswing, with fewer restrictions in certain areas. Anthropic leaders stress that disentangling biological capabilities from misuse risk remains especially challenging, and that a separate trusted access program is planned for life‑science organizations.
This two‑track strategy – Fable for the public, Mythos for vetted partners – shapes both the optimism and unease in community reactions.
Fable 5 Samples and Use Cases
The most vivid illustration of Fable 5’s capabilities comes from real‑world projects and internal pilots rather than benchmark charts. Anthropic and early partners have shared several examples.
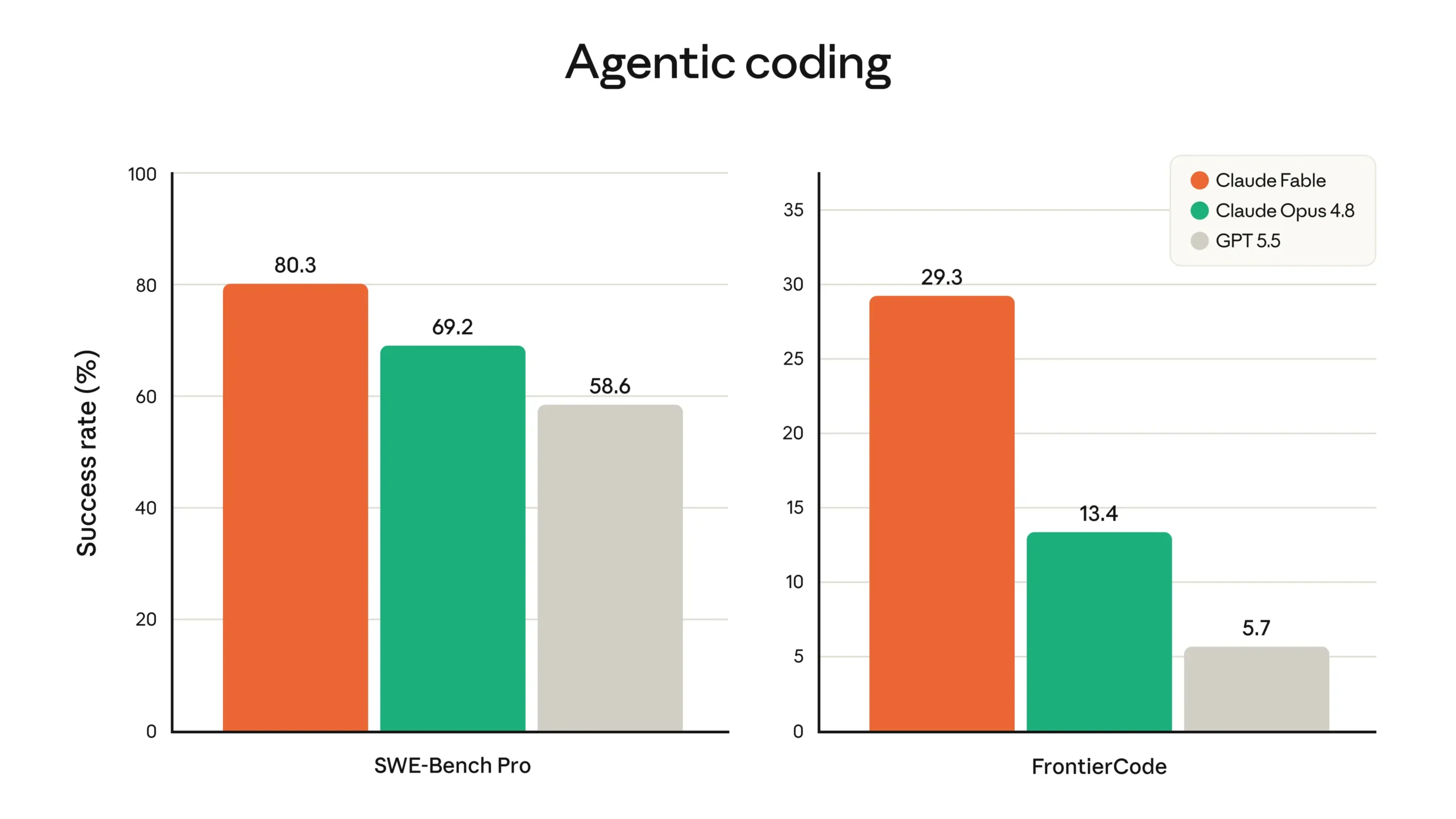
Payments company Stripe, an early tester, reports that Fable 5 performed a codebase‑wide migration of a 50‑million‑line Ruby codebase in a single day – work estimated to take a team of engineers more than two months otherwise. According to Anthropic, the model compressed “months of engineering into days” on multiple projects, including automated refactors and large‑scale configuration edits.
There are more playful but telling demos as well. An Every.to “vibe check” describes Fable 5 as “the best coding model in the world” and documents one‑shot builds of complex applications, from a fully interactive “Library of Babel” game inspired by Borges to a browser-based “Breathwork Garden.” YouTube breakdowns show the model designing and coding a playable RollerCoaster Tycoon‑style game in under an hour.
GitLab, which integrated Fable 5 into its Duo Agent, reports “measurable improvement in first‑shot correctness on complex, well‑specified problems” and fewer back‑and‑forth iterations when generating patches for real‑world repositories. In the legal domain, Crosby Legal, an AI-first law firm said that in blind tests “Fable 5 feels materially different” and that its contract redlines matched or beat their incumbent model in quality.
Taken together, these early samples suggest Fable 5 is particularly strong whenever the task is clear, high stakes and involves reading, reasoning over and rewriting large volumes of structured text or code.
Fable 5 Comparisons
Benchmarks show Fable 5 holding a clear lead over GPT‑5.5 and Gemini 3.1 Pro on several demanding tasks, but real‑world comparisons are more nuanced.
One deep dive concludes that Fable 5 “leads the public board on the kind of work businesses actually do,” particularly on SWE‑Bench Pro and code reasoning, but recommends routing workloads dynamically: Fable for hardest problems, cheaper models like Opus or GPT‑5.5 for routine tasks. Google’s own documentation positions Fable 5 as a specialized option within its Gemini Enterprise Agent platform, optimized for long‑running autonomous knowledge work and coding, rather than a general replacement for Gemini 3.1.
Well-known AI practitioners echo that split view. In an X thread, Andrej Karpathy calls Fable 5 a “major‑version‑bump‑deserving step change,” noting that both benchmarks and qualitative feel confirm it as state‑of‑the‑art across software engineering, knowledge work and scientific research.
Other reviewers emphasize trade‑offs. Simon Willison describes his initial impressions as “this is something of a beast,” but also flags that it is “slow, expensive” and prone to hitting safety rails in areas like security research.
For many organizations, the practical question is less “Which is absolutely best?” and more “When does Fable’s extra capability justify the higher cost and longer latency?” Early evidence suggests the answer is: less often than marketing might imply, but often enough to matter for high‑impact workloads.
Fable 5 Reviews and Opinions
Several long‑form reviews have already dissected Fable 5’s behavior in depth.
Every.to’s “Vibe Check” argues that Fable 5 is “the best coding model in the world” and gives it a 91/100 on a custom “Senior Engineer benchmark” focused on complex, multi‑file changes with minimal prompting. It highlights particularly impressive performance when Fable is allowed to run as an autonomous agent – planning, executing and verifying changes over many steps – rather than as a simple chat assistant.
Lenny Rachitsky’s newsletter offers a more product‑manager’s perspective, praising Fable 5’s long‑horizon planning and reliability on real work tasks but urging teams to think carefully about routing, cost control and how often they truly need Mythos‑class capability. In mainstream business media, outlets like Inc., CNBC and the Wall Street Journal frame Fable 5 as a milestone in the “frontier AI” race, while repeatedly returning to the tension between its power and the strict safeguards required to make it palatable to regulators and enterprise buyers.
Across these reviews, a consensus emerges: Fable 5 is a genuine step up in capability, particularly for code and long-context reasoning, but not a magic button. Getting value from it will require thoughtful integration, task design and acceptance of its deliberate guardrails.
What Reddit users are saying – Power, refusals and “AI inequality”
On Reddit, reactions to Fable 5 are more visceral – and more divided.
In the r/ClaudeAI and related communities, early megathreads collect reports from users who immediately pushed the model to its limits. One widely upvoted post complains that “Fable 5 feels less like a model launch and more like a preview of AI inequality,” arguing that the public version is clearly weaker or more restricted than the Mythos preview shown to select partners. Another notes that “the tradeoffs are visible from the first prompt,” pointing to frequent refusals on anything touching security, even for clearly legitimate research or defensive purposes.
Some users praise the performance, especially for game development and complex coding tasks. A poster in r/vibecoding shares a video of someone on X “vibecoding” an entire game with Fable 5 “in just 1 prompt”.
someone on twitter just vibecoded this game using Claude fable 5 most powerful AI model till now in just 1 prompt, looks like it is over for chatgpt now
byu/FoundationRude9871 invibecoding
Others describe Fable 5 as “performing exceptionally well on agentic coding benchmarks” and note that it is priced at $10/$50 per million tokens, consistent with official announcements.
claude fable 5 just dropped and i genuinely cannot keep up anymore. how do you all stay on top of this stuff?
byu/Complete-Sea6655 inAnthropic
At the same time, frustration over guardrails is common. One argues that the model “always assumes the worst from the request” and that safety filters sometimes block clearly benign experimentation.
Unpopular opinion: Claude Fable 5 feels like a gimmick
byu/External_Swan2340 inClaudeCode
Another commenter in a benchmarks thread points out that some of the headline scores rely on Mythos results rather than the exact Fable configuration the public can access, and that for a subset of benchmarks there is “no enhancement over 4.8” at all.
Comment
byu/reddit4jonas from discussion
insingularity
Overall, Reddit sentiment reads as cautiously impressed but heavily focused on the boundaries: where Fable 5 shines, where it refuses, and what that implies about who gets access to the “full” model.
Fable 5 on X – Hype, caveats and cost complaints
On X (formerly Twitter), the tone leans more enthusiastic, especially among AI builders and early‑access partners.
Anthropic executives describe Fable 5 as a Mythos‑class model “made safe for general use” and emphasize that it is “far better than any model we’ve ever released on long‑running tasks.” Threads from AI researchers and founders highlight both the benchmarks and qualitative feel; one popular post calls it “a major step change forward” and stresses that its lead grows as tasks become longer and more complex.
Developers using Claude Code and Cowork report that Fable 5 is “the best model I have used for coding, by a wide margin,” citing fewer prompts, better tool use, stronger self‑verification and higher trust in autonomous sessions.
Another AI engineer contrasts Fable 5 with GPT‑5.5 and describes OpenAI’s model as “feeling like a toy” by comparison when working on deep codebase refactors.
Not all posts are glowing. Others question whether Anthropic’s conservative safety choices will leave room for competing models that are slightly less capable on benchmarks but perceived as more “useful” day to day because they say yes more often.
Even so, across X the emerging narrative is that Fable 5 marks a new high‑water mark for publicly accessible AI – one that also makes the gap to still‑closed systems painfully obvious.
How to decide if Fable 5 fits your use case
Given the mix of power, price and guardrails, Fable 5 is not a universal recommendation. Whether it makes sense depends heavily on what you are trying to do.
For large engineering organizations, the case is strongest. If teams are routinely working with multi‑million‑line codebases, complex migrations or refactors and long‑running agents, Fable 5 appears to offer real time savings relative to both Opus 4.8 and competitor models, as Stripe’s internal results suggest. In that world, doubling model cost but cutting delivery time by weeks can be a clear net win.
For startups and individual developers, the calculus is more delicate. Many indie game devs and tool builders experimenting with Fable 5 report dramatic quality improvements but also bump into refusals and sticker shock; Reddit threads are full of users debating whether the marginal gains justify the higher bills when Opus, GPT‑5.5 or Gemini 3.1 Pro already feel “good enough” for their current use. Knowledge workers, researchers and legal professionals face similar trade‑offs: if a single Fable‑powered workflow saves hours or days, occasional use can pay for itself, but it may not make sense as the default assistant for everything.
For casual users, Fable 5’s launch window inside consumer‑style subscriptions offers a risk‑free way to experiment – but after the promotional period, it will likely become a power‑user feature rather than a mass‑market default. If the priority is affordability and a friendly chat interface over raw capability, other Claude models or competing assistants may remain the better fit.